Ces derniers mois, travailler sur mon site web s'est révélé être de plus en plus pénible, que ce soit pour continuer à le développer, itérer sur son design, écrire un article de blog ou mettre à jour mes pages conférences et ateliers. C'était dû en partie à Jekyll, le générateur de site statique que j'utilisais alors. Le vent du changement commençait à souffler.
Jekyll était devenu incroyablement lent et chaque changement entraîne une recompilation… C'était devenu tellement lent qu'attendre que la compilation du site soit terminée est devenue une vraie torture, tellement chronophage qu'il fallait que je m'en débarrasse à tout prix.
On pourrait croire que j'exagère, mais je vous promets que non. Jekyll est devenu beaucoup trop lent. "Trop lent" est en réalité un euphémisme. Dernièrement chaque fois que je modifiais une propriété CSS ou que j'effectuais une modification du code HTML je devais attendre jusqu'à cinq minutes pour que le changement soit pris en compte et compilé par Jekyll. Encore une fois je n'exagère pas. Jekyll se figeait littéralement. Il fallait que je l’arrête en faisant CTRL-C pour débloquer la situation et que je le relance pour que les changements soient pris en compte et qu'il finisse par compiler. Et si j'effectuais beaucoup de changements d’affilée, le ventilateur de mon Macbook commençait à s'emballer comme un fou, l’ordinateur chauffait et faisait le bruit d’un avion sur le point de décoller. 1
Je dirais que mon site est de taille modeste. J'ai moins d’une centaine de billets de blog, même moins de 60 à l’heure où j'écris cet article, et seulement quelques pages statiques. Je ne me repose pas beaucoup sur JavaScript. En fait, j'ai à peine besoin d’utiliser la moindre ligne de JavaScript. Et pourtant, Jekyll avait du mal à chaque fois qu'il devait compiler.
Oui, j'ai utilisé des options comme --incremental et toutes celles que l’on
m'a recommandées pour accélérer le processus de compilation. Sans le moindre
résultat.
J'ai même du mal à souligner à quel point cela a empiré ces douze derniers mois. Je ressentais littéralement une montée d’hormones de stress dans mon flux sanguin à chaque fois que j'imaginais que je devais apporter un changement à mon site Web. Je savais que j'allais vivre un enfer en faisant cela.
Mais je savais que cela ne pourrait durer éternellement. Je savais que je devrais laisser tomber Jekyll et migrer à un moment donné vers un nouveau générateur. Je n'ai simplement jamais eu le temps de le faire. Pour être honnête, je n'ai jamais vraiment pris le temps de le faire, car à chaque fois que j'avais du temps de libre je voulais profiter au maximum de ce temps en restant éloignée de mon ordinateur. Mon site n'était simplement pas une priorité, surtout que j'étais encore indécise sur l’alternative à utiliser. Du coup j'ai continué de le laisser en l’état.
Mais dernièrement, sachant que j'avais quelques semaines de libres pour faire ce que je voulais et comme j'ai commencé à avoir plein d’idées pour mon blog et que je voulais vraiment qu'elles voient le jour, comme mettre en place une lettre d’information, modifier le design, améliorer le code (un travail toujours en cours), ajouter un nouveau type de contenu (c'est pour bientôt) et quelques autres idées, j'ai finalement réussi à m'y mettre et à le faire, car je voulais que mes idées prennent forme et écrire quelques billets de blog. Mais d’abord j'avais besoin de pouvoir de nouveau prendre du plaisir à travailler sur mon site web. Du coup je me suis dit : "Ça suffit, je vais devoir m'y mettre pour de bon pendant quelques jours cette semaine et dédier du temps à passer à un nouveau générateur de site statique". Je savais que c'était un investissement personnel nécessaire et extrêmement utile que je devais me résoudre à faire. Je m'y suis investie et je l’ai fait. (C’est vraiment la manière la plus efficace d’être productif : le faire.)
Choisir un générateur de site statique
Comme je l’ai dit plus haut, une des raisons pour laquelle je n'ai pas changé de générateur plus tôt c'est parce que je ne savais pas lequel je voulais utiliser. Plusieurs personnes sur Twitter m'ont gentiment suggéré quelques-unes des nombreuses options disponibles. Mais aucune de ces options ne m'allait. Voyez-vous, chaque personne a son propre mode de fonctionnement et ses préférences lorsqu'il s'agit d’organiser ses fichiers, ses dossiers et son travail. Aucun des générateurs statiques que j'ai regardés n'avait ce que je recherchais pour mon site. Jusqu'à ce que quelqu'un me suggère de jeter un œil à Hugo.
J'ai passé la documentation en revue quelques minutes, simplement pour me faire une idée de ce à quoi je pouvais m'attendre et de ce que Hugo avait à offrir – histoire d’avoir une première impression, à proprement parler. Après avoir lu la partie sur la structuration des contenus et leur organisation et appris comment Hugo offre la possibilité de créer plein de sections et de catégories de contenus différents, en plus de la souplesse générale qu'il procure, je me suis dit que c'était le générateur de site statique dont j'avais toujours rêvé et celui dont j'avais besoin. L'organisation et la structure ressemblait exactement à ce que j'avais pu imaginer pour mon propre site.
Mais ce qui m'a fait adopté Hugo plus que toute autre option, c'est de voir à quel point il est rapide comparé à Jekyll. Non seulement chaque billet de blog que j'ai pu lire y est allé d’une comparaison qui atteste ce fait, mais j'ai aussi pu faire l’expérience de cette vitesse pour la première fois lorsque j'ai travaillé sur la refonte de Smashing Magazine.
La nouvelle version de Smashing Magazine (actuellement accessible via next.smashingmagazine.com) utilise Hugo comme générateur de site statique. La configuration que j'ai utilisée lorsque je montais le front-end du magazine s'est montrée tellement rapide que je n'avais aucun doute quant à la véracité des résultats que je pouvais lire. Et comme mon site est bien plus petit que Smashing Magazine, je savais que je n'avais aucun souci à me faire. Si Smashing Magazine pouvait être compilé aussi rapidement, pourquoi pas mon blog ?
Configurer Hugo
Configurer Hugo n'est pas compliqué. Il y a deux guides dans la documentation : un pour installer Hugo sur un Mac et un pour l’installer sur Windows. Dans cet article je ferai toujours référence à la configuration pour un Mac, puisque c'est ma principale machine de travail.
J'ai utilisé brew pour installer Hugo :
brew install hugoJ'ai suivi les instructions présentes sur la page d’installation, mis à jour
brew et lancé quelques commandes pour m'assurer que tout était bien installé
et fonctionnait correctement. C’est tout ce dont vous avez besoin pour qu'Hugo
tourne sur votre machine. Difficile de faire plus simple. Avec Jekyll, ce
n'était pas aussi indolore, je me rappelle avoir passé pas mal de temps à le
configurer pour le faire tourner à l’époque.
J'ai parfois tendance à être une développeuse paresseuse. Mais ça a du bon, car cela me pousse à trouver la manière la plus rapide et la plus simple de mener à bien une tâche. Et donc la première des choses que j'ai voulu faire a été de migrer automatiquement tous mes articles de blog dans Hugo sans avoir à repasser sur chacun des billets pour modifier le front matter. (J'aurais vraisemblablement abandonné si j'avais dû faire cela 😅)
Heureusement, depuis la version 0.15, Hugo offre
une commande pour migrer depuis Jekyll.
Vous n'avez qu'à taper la ligne suivante dans le terminal – en remplaçant
chemin_site_jekyll et repertoire_destination par les chemins vers le
répertoire utilisé actuellement pour votre site sous Jekyll et celui dans lequel
vous voulez configurer votre nouveau site – et Hugo se chargera d’importer les
fichiers de votre installation actuelle de Jekyll dans le répertoire qui
contiendra votre site Hugo :
hugo import jekyll chemin_site_jekyll repertoire_destinationSi vous n'importez pas un site depuis Jekyll, vous pouvez toujours aller lire la documentation qui détaille ce qu'il faut savoir sur la structure des répertoires de Hugo, où ranger les assets, le contenu, les modèles de mise en page et bien plus.
L'étape suivante consiste à convertir vos modèles Jekyll en modèles Hugo et c'est là où réside la plus grande partie du travail et où je me suis arrachée les cheveux pas mal de fois. Mais croyez-moi, le résultat final prouve que ça valait vraiment le coup. Au passage, j'ai beaucoup appris. C’est ce que je vais partager avec vous dans la prochaine section.
Se plonger dans Hugo : quelques détails techniques
Laissez-moi commencer en vous disant qu'à un moment donné pendant la migration, je ne faisais que modifier des trucs, changer des valeurs, des noms de fichiers, la structure, etc. dans l’espoir que les choses allaient marcher comme par magie et, quand ce n'était pas le cas, je me disais alors : "Je n'ai aucune idée de comment ou pourquoi ce truc marche". Et comme l’a dit quelqu'un sur Twitter, apparemment je ne suis pas la seule à avoir subi ce genre de choses avec Hugo. J'espère donc que cet (assez long) article aidera certains d’entre vous à passer à Hugo, et vous évitera au passage quelques maux de têtes.
Avertissement : Il y a encore beaucoup de choses que je ne sais pas encore faire et où je me retrouve parfois à devoir chercher sur Internet. Mais j'ai acquis toutes les connaissances de base et de tout ce dont j'ai besoin pour le moment pour avoir un système fonctionnel, et oui, je sais comment et pourquoi tout ce qui marche maintenant marche de cette manière. Donc laissez-moi vous dévoiler tout ça. Je vous partagerai aussi les articles super utiles que j'ai trouvé et qui m'ont également bien aidé. Prenez cet article comme un pense-bête, un ensemble de rappels, une note à mon futur moi à laquelle je devrai revenir si jamais j'ai besoin de revoir les bases.
La structure des dossiers d’Hugo
La structure du répertoire de mon site en local ressemble actuellement à ça :
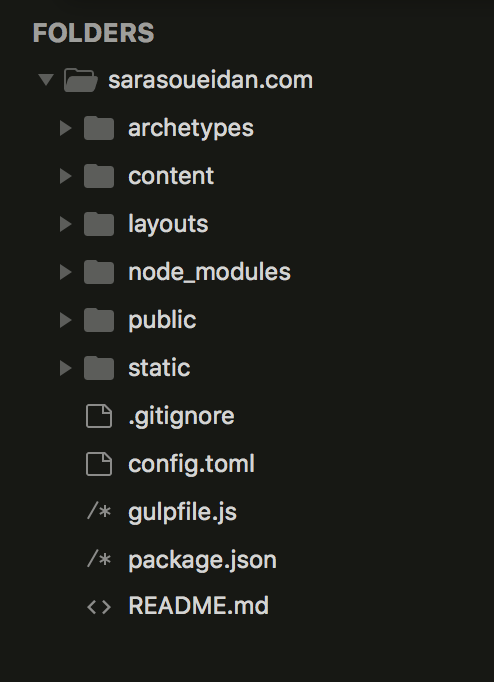
Les dossiers que vous pouvez voir sur l’image ci-dessus, à l’exception du
dossier node_modules sont ceux générés pour vous par Hugo lorsque vous
importez votre site depuis Jekyll, ce sont ceux que vous devriez normalement
créer pour un site géré avec Hugo.
Les fichiers du bas sont ceux qui sont nécessaires et utilisés par Git et Gulp.
Le seul fichier qui est utilisé par Hugo est le fichier config.toml.
config.toml contient la configuration de variables du site comme baseURL
parmi beaucoup d’autres variables que vous allez décider d’utiliser ou pas. Ce
fichier est similaire au fichier de configuration YAML de Jekyll. La
documentation d’Hugo liste
toutes les variables disponibles et
ce que vous devez savoir pour pouvoir utiliser celles dont vous avez besoin. Mon
fichier de configuration ne contient pas beaucoup de variables pour le moment.
Votre site est compilé dans le répertoire /public/. Il correspond au dossier
dist qu'on retrouve dans beaucoup d’arborescences d’applications. C’est dans
tous les autres dossiers que va se dérouler le développement.
Le dossier static est destiné à héberger les contenus statiques comme les
images, les fichiers CSS et JS mais aussi les fichiers audio, vidéo, les slides
de présentations, etc. Je passe pas mal de temps à travailler dans ce dossier.
Créer et mettre en page du contenu
Pour chaque type de contenu dont vous avez besoin, que ce soit une page, un
billet de blog, un index de vos articles, de vos études de cas, etc. vous allez
devoir créer un fichier Markdown (.md) dans le dossier /content/. C’est là
où sont stockés tous les contenus. Après avoir créé le contenu dans son
répertoire spécifique, vous allez créer ou réutiliser un modèle de mise en page
stocké dans le dossier /layouts/.
Chaque fichier .md du dossier /content/ correspond à une page qui commence
avec une entête front matter, écrite au format yaml ou toml.
Puisque je voulais m'imprégner d’un nouvel environnement et que la plupart de la
documentation et des ressources dédiées à Hugo utilisent le format toml, c'est
le format que j'ai utilisé. Jekyll utilise yaml.2
Définir (ou déclarer) les types de contenu
Le front matter de chaque page définit le type de page ou de
contenu qui à son tour définit le type de modèle qui sera utilisé pour le rendu.
Le type de page est défini par la variable type. Par exemple le front matter
d’un article dans la section blog de mon site ressemble à ça:
+++
type = "blog"
description = "…"
title = "…"
date = …
…
+++La valeur type peut prendre pratiquement n'importe quelle
valeur, et c'est là où on peut se rendre compte du pouvoir
d’Hugo. Vous pouvez définir autant de types de contenus que vous voulez. Par
exemple, j'utilise actuellement cinq types de contenus pour mon site :
statique (pour les pages comme "À propos" et "Travailler avec moi"), blog
(pour les articles comme celui que vous êtes en train de lire), ateliers,
études de cas et bureau (un nouveau type d’articles à paraître bientôt). Je
peux créer autant de types de contenu que je veux.
C’est une des choses que j'aime chez Hugo comparativement à Jekyll qui, à ma connaissance, n'offre pas de fonctionnalité similaire.3
La capture d’écran ci-contre montre à quoi ressemble mon dossier /content/ en
ce moment :
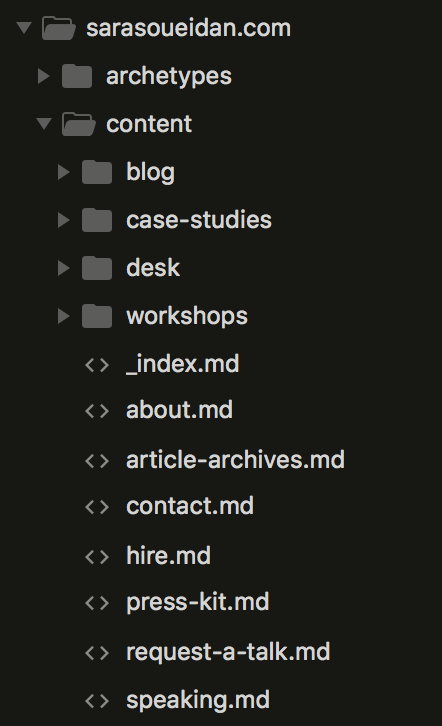
content de mon site.Les pages statiques sont créées dans des fichiers individuels au format Markdown
à la racine du dossier /content/. Les autres types de contenus qui auraient
besoin d’un index (comme des articles, des ateliers, des études de cas, etc.)
sont créés dans des dossiers nommés d’après le type de contenu. Par exemple on
stockera les contenus de type ateliers dans un dossier /content/ateliers/.
Mes articles se trouvent dans le répertoire /content/blog/. {{< marker >}}Les
dossiers de ce type sont également appelés des sections.{{< /marker >}}
Pour chaque contenu, il vous faut définir son type. Vous pouvez faire ça de deux manières.
Le type pour les pages statiques est défini à l’aide de la variable type dans
l’entête front matter de la page. Le type des sections (blog,
ateliers, études de cas et bureau) est quant à lui défini à l’aide de
l’arborescence de dossiers. Vous n'avez pas besoin de spécifier le type dans le
front matter lorsque vous vous reposez sur l’arborescence de fichiers. Par
exemple un billet de blog qui se trouve dans le dossier /content/blog/ sera
automatiquement traité comme un type de contenu blog. Inutile de le préciser
dans le front matter de chaque article.
Vous pouvez choisir de définir le type de contenu à l’aide du front matter ou de
l’arborescence de fichier. Généralement vous utiliserez la variable type pour
les pages statiques et vous vous reposerez sur l’arborescence de fichiers pour
les contenus qui auront besoin d’un index, par exemple des billets de blog.
Une chose importante à savoir est que {{< marker >}}si vous définissez le type
de page à l’aide de la variable type, la page peut se trouver n'importe où
dans le dossier /content/, l’arborescence n'aura alors aucune importance.{{%
/marker %}}
Vous pourriez donc attribuer le type static à une page et la placer dans le
dossier blog et Hugo la considérera comme une page statique et ne tiendra pas
compte de sa place dans l’arborescence.
Mais… pourquoi donc ? Réponse : pour choisir le type de modèle à utiliser.
Voyez-vous, chaque type de contenu est associé avec un certain type de mise en page. Vous pouvez également utiliser un même modèle pour plusieurs types de contenu. Nous verrons cela dans la partie suivante. Mais d’abord, créons quelques pages de contenus : deux pages statiques (Accueil et À propos par exemple) et une page d’index pour les articles de blog.
Avant de faire cela, j'aimerais préciser quelque chose quant à la création de pages d’index pour différentes sections ou types de contenu.
La section blog nécessite la présence d’un fichier _index.md dans le dossier
/content/blog/. C’est le fichier d’index pour cette section (celui grâce
auquel nous afficherons la liste de tous les articles). Le dossier
/content/blog/ hébergera également tous les billets de blog. La capture
d’écran suivante montre cela de façon plus visuelle :
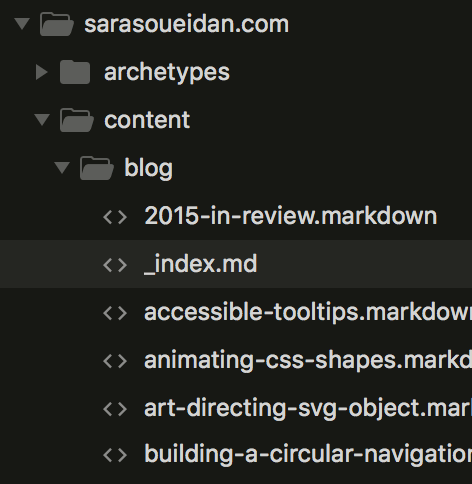
/content/blog/.Chaque type de contenu qui utilise cette arborescence de dossiers (ou chaque
section de contenu) comporte une page d’index qui commence par un tiret bas
(_) en plus des fichiers de cette section. De la même manière, tout autre type
de contenu (ou section) comportera aussi un index et des fichiers pour cette
section.
OK, créons maintenant quelques pages.
La page d’accueil
La page d’accueil se crée en plaçant un fichier nommé _index.md dans le
dossier /content/ comme vous pouvez le voir dans la capture d’écran un peu
plus haut.
La page d’accueil est un peu spéciale, c'est la seule de toutes les autres pages
qui nécessite d’avoir son propre modèle de mise en page dans le dossier
/layouts/ – nous parlerons de ces modèles plus en détail dans la prochaine
section – et ce modèle de mise en page se nomme aussi index.html.
Vous définissez le type page dans le front matter du fichier
/content/_index.md et vous lui attribuez un titre ainsi qu'une description.
Le front matter de ma page d’accueil ressemble à ça :
+++
type = "page"
title = "Accueil"
description = "Sara Soueidan — Développeuse Web Front-end, auteure et conférencière"
+++La description est utilisée dans le fichier partiel d’entête du site en tant que
valeur de l’attribut <title> ainsi :
<title> {{ .Page.Description }} </title>La raison pour laquelle je n'utilise pas la valeur du title dans le front
matter pour la balise HTML <title> est que dans les autres pages, le title
de la page est aussi utilisé comme intitulé de lien dans le menu principal de
navigation. Mais nous verrons tout ça plus tard.
Les fichiers Markdown (.md) peuvent contenir du Markdown et du HTML et, comme
pour la page d’accueil, je n'ai aucune entrée dynamique (comme une liste
d’articles), elle contient juste le code HTML de la page. Mais comment ce code
Markdown et HTML sont-ils mis en forme ? Et comment fait-on pour inclure un
entête et un pied de page ? Tout cela se passe dans le modèle de mise en page.
Le fichier /layouts/index.html est la mise en page utilisée pour l’accueil et
voici à quoi il ressemble :
{{ partial "homepage-header.html" . }}
{{ .Content }}
{{ partial "footer.html" . }}{{ .Content }} récupère le contenu de la page correspondante
dans le dossier /content/. Donc ici ça récupère le contenu de
la page d’accueil à partir du fichier /contents/_index.md.
En outre, j'appelle l’entête ainsi que le pied de page à l’aide de fichiers partiels.
Par défaut, quand vous demandez partial "footer.html .", Hugo va
regarder s'il existe un fichier partiel dans le dossier partials situé dans le
répertoire layouts.
Reportez-vous à la documentation d’Hugo sur les fichiers partiels pour savoir ce que veut dire le point à la fin, ce qu'il fait et comment on peut personnaliser les appels à des fichiers partiels.
Et voilà comment on crée une page d’accueil pour son site : un fichier
/content/_index.md qui contient le contenu de la page d’accueil, lui-même mis
en page à l’aide du fichier /layouts/index.html.
Ajouter une page statique
Une fois la page d’accueil terminée, j'ai voulu m'occuper du reste des pages statiques avant de passer à des contenus plus dynamiques. Je me suis donc mise à bâtir la page À propos.
J'ai dû faire pas mal de recherches et lire quelques fils de discussions d’aide sur le forum d’Hugo et ailleurs pour y parvenir. J'espère donc que ce billet vous sera bénéfique si vous cherchez à créer des pages statiques, ce qui s'avère étonnement simple en fait.
Les pages statiques sont créées à la racine du répertoire /content/, tout
comme la page d’accueil. Toutefois, contrairement à la page d’accueil, les noms
de fichiers ne commencent pas par un tiret bas.
Et contrairement à la page d’accueil, vous allez devoir définir le type de page et dire à Hugo de l’inclure dans le menu principal du site, en lui attribuant un titre et une description.
Pour la page À propos de mon site, j’ai créé un fichier /content/about.md.
Le front matter de la page est le suivant :
+++
type = "static"
page = "static/single.html"
title = "À propos"
description = "À propos de Sara Soueidan — Développeuse Web front-end, auteure et conférencière"
menu = "main"
weight = "1"
+++Notez la valeur de type. Comme dit plus haut, vous pouvez attribuer ici la
valeur de votre choix. J'ai choisi static, car ça décrit littéralement le type
de la page. Et aussi parce qu'on trouve beaucoup de ressources en ligne qui
utilisent ce type pour les pages statiques.
La variable page indique à Hugo quel modèle de mise en page présent dans le
répertoire /layouts/ utiliser.
Le title est utilisé comme intitulé de lien dans le menu. (Sur mon site le
menu situé en haut de page contient une entrée "About & Interviews").
Je vous ai déjà dit que la description est utilisée dans le fichier partiel
qui gère l’entête de page, cette description apparait ensuite dans l’onglet de
votre navigateur.
La variable menu indique à Hugo que cette page doit avoir une
entrée dans le menu principal.
La variable weight est très utile pour vous aider à définir
l’ordre d’affichage des liens dans le menu. Si vous ne l’utilisez
pas, Hugo utilisera son propre ordre par défaut – qui n'était pas celui que je
souhaitais pour mon site. Vous pouvez également définir des valeurs négatives
pour cette variable.
Toutes les autres pages statiques sont créées de la même manière. La seule chose qui change c'est le titre, la description et leur ordre dans le menu. Elles utilisent toutes le même modèle de mise en page.
Je me note quelque chose ici pour plus tard :
Hugo respecte un ordre spécifique pour décider du modèle de mise en page à
utiliser pour chaque page créée dans le dossier /content/. Nous en reparlerons
dans la section dédiée aux modèles juste après. Donc si nous n'avions pas défini
le fichier /layouts/static/single.html comme étant le modèle à utiliser, Hugo
aurait utilisé un modèle par défaut stocké dans /layouts/. Nous y
reviendrons.
Enfin, comme pour la page d’accueil, le contenu HTML de la page À propos se
trouve dans le fichier about.md puis il est ensuite inséré dans le modèle
/layouts/static/single.html à l’aide de {{ .Content }}. Nous faisons aussi
appel aux fichiers partiels d’entête et de bas de page. Notez la correspondance
entre le type static et le dossier static situé dans layouts qui contient
le modèle de mise en page.
Les archétypes de contenu
Vous avez peut-être remarqué sur la capture d’écran plus haut que j'ai aussi un
dossier nommé /archetypes/ à la racine de mon site. Ce dossier est lui aussi
lié aux types de contenu que vous créez. Mais il a un but bien précis.
Pour expliquer à quoi sert ce répertoire, je vais commencer par citer la page correspondante de la documentation d’Hugo :
Les archétypes vous permettent de créer de nouvelles instances de types de contenu et de définir des paramètres par défaut à partir de la ligne de commande.
Les archétypes sont des fichiers de contenu stockés dans le répertoire
archetypesde votre projet, qui contiennent un front matter pré-configuré pour les types de contenu de votre site web. Les archétypes facilitent la consistance des métadonnées des contenus à travers tout votre site et permettent aux auteurs de générer rapidement de nouvelles instances de type de contenu à l’aide de la commandehugo newHugo est capable de déduire l’archétype approprié à l’aide de la section de contenu passée en argument de la commande
new:
hugo new <section-de-contenu>/<nom-de-fichier.md>
En d’autres mots, définir un archétype vous permet de créer de nouveaux contenus plus rapidement, puisqu'il va remplir le front matter de notre nouvelle page avec les variables de votre choix.
Par exemple, supposons que je veuille créer une nouvelle étude de cas (qui irait
dans /content/etudes-de-cas/). Au lieu de créer un nouveau fichier Markdown
dans le répertoire, je peux taper cette commande dans le terminal et Hugo va
créer le nouveau fichier pour moi :
hugo new etudes-de-cas/ma-nouvelle-etude-de-cas.mdEt les variables de cette nouvelle étude de cas (ma-nouvelle-etude-de-cas.md)
seront automatiquement ajoutées : nom du client, logo du client (chemin vers
l’image), description du client, description du projet, date du projet, etc. Par
défaut les valeurs de ces variables seront vierges, prêtes à être renseignées.
La capture d’écran suivante montre les variables front matter que j'ai définis
pour l’archétype etudes-de-cas :
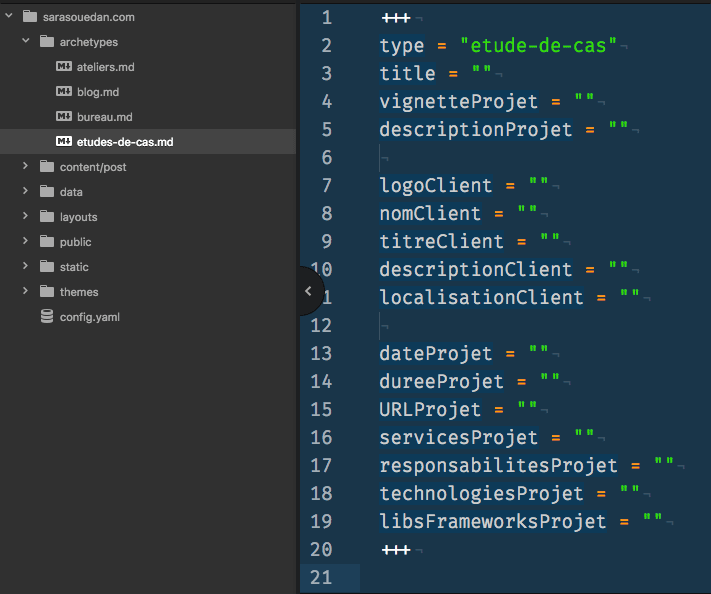
Notez aussi que les autres archétypes que j'ai définis dans le répertoire
archetypes qui correspondent aux quatre autres types de section qui figurent
sur mon site. C’est à peu près tout ce qu'il faut savoir sur les archétypes. Si
vous souhaitez en savoir plus, reportez-vous à la page dédiée dans la
documentation d’Hugo. C’est bien expliqué. Vous n'êtes pas obligés de définir
des archétypes, mais je pense que vous en aurez envie.
Présenter le contenu avec les modèles de page et créer une page d’index pour les billets
C’est la partie avec laquelle j'ai eu le plus de mal au début. Comment est-ce que je sais que tel modèle est utilisé pour telle section ? Comment est-ce que je sais de combien de modèles j'ai besoin ? Et est-ce qu'il y a vraiment besoin de modèle ?
J'ai pas mal trifouillé et cherché sur le net, puis j'ai passé le plus clair de mon temps à faire des essais, jusqu'à avoir des modèles qui fonctionnent bien. Puis j'ai tout cassé et refait les choses pour comprendre quand et comment ça fonctionnait. Je peux maintenant affirmer avec assurance que j'ai bien compris tout ça.
En général, pour un blog très simple, vous n'aurez besoin que de deux modèles
par défaut : list.html et single.html.
Le modèle list.html aura pour mission d’afficher des listes d’éléments, comme
sur la page d’index où sont affichées la liste de vos billets de blog.
Quant au modèle single.html, comme vous l’aurez deviné, il servira pour mettre
en forme les pages uniques comme celle d’un billet de blog.
Ces deux modèles doivent se trouver dans le répertoire /layouts/_defaults/.
Ainsi, si vous créez un blog avec quelques articles et ne donnez aucune
instruction particulière à Hugo à propos de leur mise en page, il ira voir dans
le dossier /layouts/_defaults/ quels modèles utiliser.
J'ai mis en place ces modèles comme solution par défaut sur mon blog, mais je les surcharge.
Vous pouvez surcharger les modèles par défaut en fournissant des modèles qui porteront le même nom que votre section ou votre type de contenu.
En d’autres termes, vous pouvez créer dans le répertoire /layouts/ une
structure de dossiers similaire à celle que vous avez dans le répertoire
/content/ et Hugo se basera sur cette structure pour déterminer le modèle à
utiliser.
Ou alors vous pouvez créer un répertoire du même nom que le type que vous avez
défini, comme static par exemple que j'utilise pour les pages statiques.
Plutôt que d’utiliser le modèle par défaut, Hugo utilisera alors le modèle situé
dans le répertoire /layouts/static/ pour toutes les pages qui auront le
type = static.
J'ai pour ma part créé le fichier /layouts/static/single.html que Hugo va
utiliser pour surcharger la mise en page des pages statiques
/layouts/_default/single.html .
Encore une fois la page /layouts/static/single.html est simplement un modèle
avec le contenu suivant :
{{ partial "header.html" . }}
{{ .Content }}
{{ partial "footer.html" . }}dans lequel le contenu est récupéré à partir des fichiers Markdown respectifs.
Donc la page about.html est générée à l’aide du modèle de page
/layouts/static/single.html et {{ .Content }} est remplacé par le contenu du
fichier /content/about.md.
Maintenant pour créer une page d’index pour une liste d’éléments, comme la page de blog et les articles listés ou la page d’ateliers et les pages de détails des ateliers, on procède de manière très similaire.
De la même manière que nous avons créé un répertoire pour le type de contenu qui
porte le même nom que le type lui-même, nous créons un répertoire pour chaque
autre type de contenu que nous avons défini à l’aide de notre arborescence de
dossiers et nous donnons à ce répertoire le même nom que celui du dossier
présent dans le dossier content.
Ou si vous préférez : de la même manière que nous avons créé un dossier dans le
répertoire layouts/ du même nom que le type de contenu, nous créons un
dossier pour chaque section de contenu (blog, ateliers, etudes-de-cas,
etc.) de manière à obtenir une structure de dossiers similaire dans layouts à
celle que nous avons dans /content/.
C’est toujours pas clair ? Alors regardez ce que ça donne pour mon site :
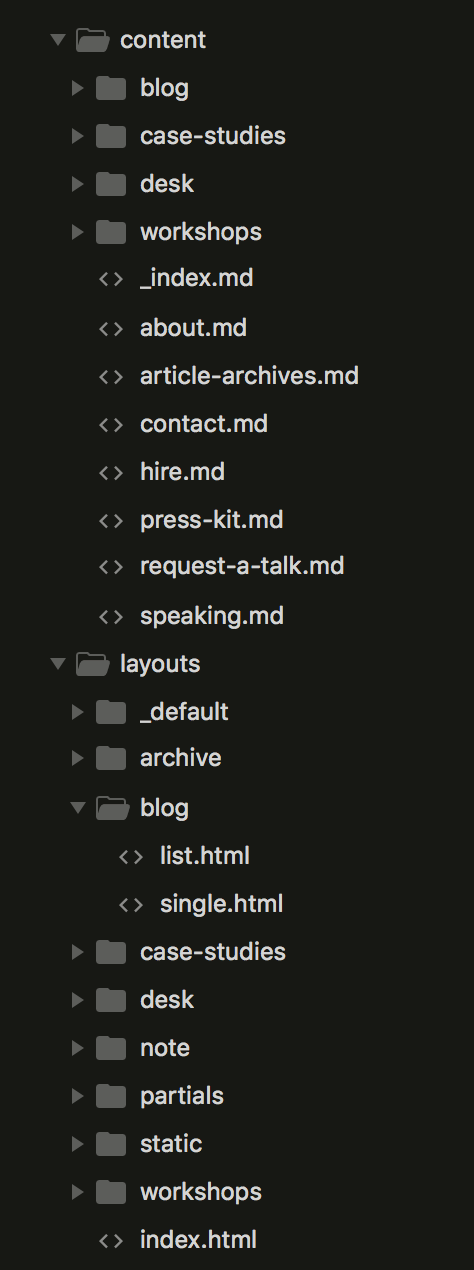
Attardons-nous à nouveau quelques instants sur la section blog. Au répertoire
/content/blog/ correspond le répertoire /layouts/blog/.
À l’intérieur du répertoire /content/blog/ se trouve la page d’index
_index.md et les articles de blog.
Dans /layouts/blog/ nous avons le modèle list.html ainsi que celui de la
page single.html.
Hugo utilisera le modèle list.html pour la page _index.md et le modèle
single.html pour chacun des articles de blog.
De la même manière, toutes les autres sections possèdent leur propre répertoire
de modèles, qui contient les modèles list.html et single.html.
Encore une fois vous n'avez pas réellement besoin de tous ces modèles. Et vous aurez peut-être remarqué que quelques-unes des pages sont en tout point similaires à l’exception de leur nom. Si je fais ça, c'est uniquement pour des raisons de flexibilité future. Si jamais je veux changer le modèle de l’un des types de section, j'aurai simplement à modifier son modèle correspondant. Si votre site est plus simple et n'utilise pas autant de types de contenus, vous n'avez surement pas besoin de créer autant de modèles que moi.
La seule exception à la structuration des répertoires de modèles c'est la page
d’accueil, dont le modèle de mise en page est placé à la racine du répertoire
/layouts/ et se nomme index.html.
Il est important de vérifier l’ordre dans lequel Hugo va choisir le modèle à utiliser pour chaque page. Je vous le recommande vivement.
Pour citer la documentation :
Hugo obéit à plusieurs règles pour savoir quel modèle utiliser pour effectuer le rendu d’une page spécifique. Hugo va utiliser la liste priorisée suivante. Si un fichier n'est pas présent, alors on utilisera le suivant dans la liste. Cela vous permet de concevoir des modèles particuliers quand vous le souhaitez sans devoir créer plus de modèles que nécessaire. Pour la plupart des sites, seul le fichier
_defaulten fin de liste sera nécessaire. Les utilisateurs peuvent spécifier le type et le modèle dans le front matter. La section est déterminée en fonction de l’endroit où se trouve le fichier de contenu. Si le type est fourni, il sera utilisé à la place de la section.
Vous en apprendrez davantage sur cet ordre de priorisation dans la page qui documente l’organisation des contenus.
Boucler sur les listes de section
Le dernier point technique sur Hugo que je veux aborder concerne le listing des articles d’une section sur la page d’index de cette section.
Une fois de plus, basons-nous sur l’exemple de la section blog située dans
/content/blog/.
Les fichiers Markdown ne contiennent bien entendu aucune logique de modèle. Donc
pour lister tous les billets de blog, nous allons devoir faire cela dans le
modèle correspondant à cette page d’index, situé dans /layouts/blog/list.html.
La boucle et toute la logique de modèle est écrite à l’aide du
templating HTML du langage Go.
La boucle en elle-même pourra et sera probablement différente pour la majorité d’entre vous. Après avoir pas mal cherché, je suis arrivée à écrire la boucle suivante qui affiche les cinq derniers articles, suivi d’un appel à un fichier partiel pour la gestion de la pagination.
<ul class="articles-list">
<!-- Boucle à travers les fichiers situés dans content/blog/*.md -->
{{ range (.Paginator 5).Pages }}
<li class="post">
<a class="post-title" href="{{.RelPermalink}}">{{ .Title }}</a>
<span class="post-meta"><time>{{ .Date.Format "January 2, 2006" }}</time> {{ if .Params.External }} — <span class="post-host">for {{.Params.External.Host}}</span> {{ end }}</span>
<div class="post-summary">
{{ .Summary }} <!-- extrait automatiquement le premier paragraphe du fichier Markdown de l’article -->
</div>
<p><small><a href="{{.RelPermalink}}" class="read-more-link">En savoir plus ››</a></small></p>
</li>
{{ end }}
</ul>
{{ partial "pagination.html" . }}C’est la partie {{ range .Paginator.Pages }} qui est vraiment importante ici.
{{< marker >}}Chaque .Paginator que vous utilisez dans une page d’index de
section va boucler et afficher les articles de cette section.{{< /marker >}}
(.Paginator 5).Pages indique à Hugo de ne lister que cinq éléments. Cette
boucle va parcourir tous les articles de la section blog et ne lister que les
cinq plus récents. Une boucle similaire dans le fichier
layouts/workshops/index.html bouclerait sur les ateliers stockés dans le
dossier /content/workshops/ et afficherait la liste des ateliers dans l’index.
Et pour ce qui est du fichier partiel pagination.html, le mien ressemble pour
le moment à ça :
{{ $baseurl := .Site.BaseURL }}
{{ $pag := .Paginator }}
{{ if gt $pag.TotalPages 1 }}
<nav class="center pagination">
{{ range $pag.Pagers }}{{ if eq . $pag }}<span class="pagination__button button--disabled">{{ .PageNumber }}</span>{{ else }}<a class="pagination__button" href='{{ $baseurl }}{{ .URL }}'>{{ .PageNumber }}</a>{{ end }}{{ end }}
<div class="clearfix">
{{ if .Paginator.HasPrev }}
<a class="pagination__button pagination__button--previous" title="Page précédente" href="{{ .Paginator.Prev.URL }}">
Articles plus récents
</a>
{{ else }}
<span class="pagination__button pagination__button--previous button--disabled">Articles plus récents</span>
{{ end }}
{{ if .Paginator.HasNext }}
<a class="pagination__button pagination__button--next" title="Next Page" href="{{ .Paginator.Next.URL }}">
Articles plus anciens
</a>
{{ else }}
<span class="pagination__button pagination__button--next button--disabled">Articles plus anciens</span>
{{ end }}
</div>
<a href="../article-archives/" class="button button--full">Voir la liste de tous les articles</a>
</nav>
{{ end }}Libre à vous d’aller en apprendre plus sur les variables. Je trouve que le code ci-dessus est compréhensible tel quel, mais encore une fois, si vous avez besoin de plus de fonctionnalités, la documentation et le forum vous seront probablement d’une plus grande aide.
Créer une page d’archive
En plus de la page de blog par défaut, je voulais ajouter une page d’archive qui liste la totalité de mes articles sur une seule et unique page. Ce n'était pas aussi évident que je l’aurais cru. La documentation ne m'a pas beaucoup aidée. Et j'ai dû à nouveau faire des recherches. Je suis tombée sur cet article extrêmement utile et j'ai eu recours à la même technique que celle exposée par l’auteur.
Pour la page d’archive, j'ai créé une page statique dans /content/ et je lui
ai donné un nouveau type: archive. La page utilise le modèle situé dans
/layouts/archive/single.html.
Dans le modèle de page, je boucle sur les articles comme pour la page d’index du blog, mais avec une différence importante :
<!-- /layouts.archive/single.html -->
{{ range where .Site.Pages "Type" "blog" }}
<li class="post">
<a class="post-title" href="{{.RelPermalink}}">{{ .Title }}</a>
<span class="post-meta"><time>{{ .Date.Format "January 2, 2006" }}</time> {{ if .Params.External }} — <span class="post-host">for {{ .Params.External.Host }}</span> {{ end }}</span>
<div class="post-summary">
{{ .Summary }} <!-- récupère automatiquement le premier paragraphe de l’article -->
</div>
<p><small><a href="{{.RelPermalink}}" class="read-more-link">Lire la suite ››</a></small></p>
</li>
{{ end }}En résumé : .Site.Pages boucle sur toutes les pages de votre
site. En d’autres termes, cela va lister tous les fichiers Markdown contenus
dans le dossier /content/. Pour indiquer à Hugo de n'afficher
que les fichiers situés dans la section /content/blog/, on “filtre” les pages
en précisant le "Type" "blog". On procédera également de la sorte pour une
page d’archive d’une autre section, en utilisant le nom de la section comme
filtre. Et c'est tout.
Héberger chez Netlify
J'avais choisi d’héberger mon site avec GitHub Pages depuis quelques années. Puis est arrivé un moment où ça commençait à faire un peu juste. Il semble qu'il y ait eu aussi régulièrement de curieux problèmes de cache et je devais pousser deux fois les changements sur le dépôt pour que ces derniers soient pris en compte (j'imagine que le cache n'était pas invalidé quand il devait l’être). J'ai donc commencé à devoir créer des enregistrements vides juste pour vider le cache et être capable de voir les changements que j'avais faits en production.
Maintenant, je ne suis pas certaine que c'était vraiment un problème de cache, bien que ça y ressemblait beaucoup. Je ne sais pas non plus si quelqu'un d’autre est capable de reproduire ce problème. Et non, je n'ai pas contacté le support de GitHub à ce sujet. Je détestais tellement mon site Web que je me suis dit "j'ai déjà assez bien de problèmes en local pour me soucier de ce problème en production", j'en ai donc fait totalement abstraction.
J'ai pu aussi me rendre compte de l’ultra-rapidité de Netlify quand j'ai travaillé sur Smashing Magazine. De plus, Netlify permet de "rendre votre site ou votre application web bien plus rapide en la servant au plus près des utilisateurs. Au lieu d’un serveur unique, vous déployez sur un réseau global de nœuds CDN intelligents, qui gère aussi l’unicité des assets, la mise en cache automatique des entêtes, les redirections et les réécritures intelligentes."
Et en plus de tout ça, si vous êtes un développeur et que vous travaillez en open source, Netlify vous offre un abonnement Pro à vie. Tout ce qu'ils demandent en retour est un lien vers Netlify sur votre site ou votre application. Pour moi ce ne fut pas un problème vu que je mentionne toujours où mon site est hébergé dans le bas de page. J'ai donc signé pour la formule Pro. Un hébergement gratuit et rapide ! Woohoo !
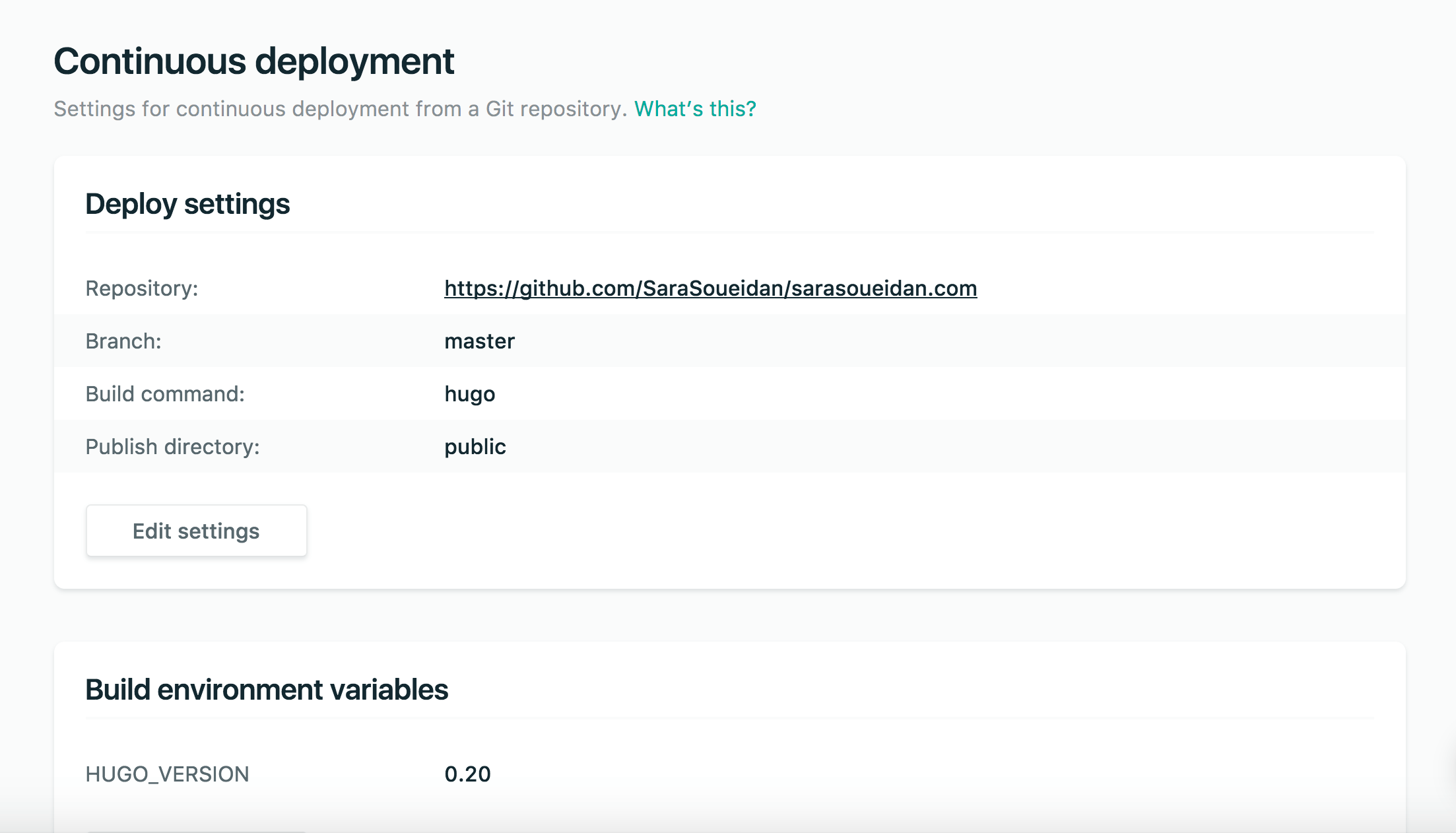
La configuration de votre site se fait en quelques clics :
- Créer un compte sur netlify.com
- Relier son compte Netlify à son dépôt de code. Le mien est hébergé sur GitHub, j'ai pu le connecter depuis l’interface de Netlify.
- Spécifier le dossier de destination ainsi que la commande de build,
respectivement
publicethugodans mon cas. (Voir les captures d’écrans ci-dessous) - Configuration de votre nom de domaine. Cela demande de faire quelques changements de DNS.
- Cela m'a demandé seulement 3 clics pour bénéficier d’un certificat SSL renouvelé automatiquement et d’une connexion HTTPS pour mon site.
- Et… c'est tout.
Je devrais probablement mentionner le fait que j'ai rencontré quelques difficultés lorsque j'ai fait la bascule, mais ce n'était pas de la faute de Netlify. L'équipe de Netlify a même été super et m'a aidée à déboguer les problèmes que je rencontrais. Après avoir effectué les changements dans la console du registrar de mon domaine, cela a pris quelques heures pour que mon site soit en ligne avec mon nom de domaine personnalisé.
Quelques bons trucs à savoir :
- Ajouter votre dossier
/public/à votre fichier.gitignore. Netlify va lancer la génération de votre site sur ses serveurs. Pour éviter de possibles conflits, ne versionnez pas votre dossier de destination dans votre dépôt. Le mien n'est présent que sur ma machine. Je rencontrais des problèmes de rendus avec certains templates quand je le versionnais auparavant. - Vérifiez bien la version d’Hugo que vous utilisez (
hugo version) et celle utilisée par Netlify. Au début j'ai eu droit à des erreurs de build qui empêchaient le déploiement, car ma version était plus récente que celle de Netlify. Si c'est le cas ajoutez une variable d’environnement à votre site qui correspond à la version d’Hugo que vous utilisez localement.
Voici en partie à quoi ressemble mon tableau de bord Netlify :
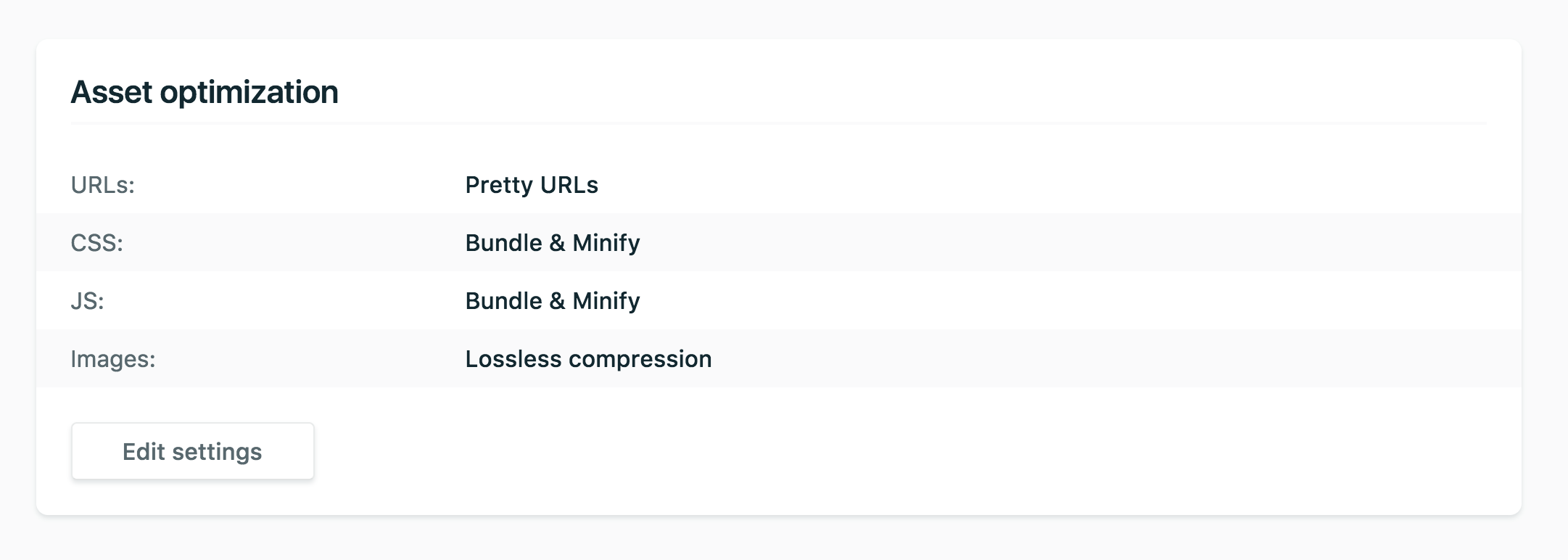
J'aime aussi le fait que Netlify propose des options pour optimiser et assembler les assets pour vous, afin d’améliorer les performances globales de votre site.
J'ai constaté quelques améliorations et plus de A verts sur la page de résultats sur webpagetest.org alors qu'ils étaient rouges auparavant. J'ai encore du travail de ce côté-là.
Résumé de ma configuration actuelle
- Le code source du site web est hébergé sur GitHub,
- J'utilise Hugo comme générateur de site statique,
- Déploiement automatiquement à chaque
pushsur le dépôt grâce à Netlify, - Hébergée gratuitement chez Netlify avec le plan Open Source.
Il est également utile de mentionner que désormais la compilation complète de
mon site après chaque changement, sans avoir à filtrer de vieux contenus, prend
à Hugo moins de 40 millisecondes. {{< marker >}}Hugo met 39ms à compiler mon
site pour être plus précis{{< /marker >}}, là où Jekyll, même avec des options
comme --incremental mettait plusieurs minutes.
Objectifs futurs
On retrouve ici quelques-unes des choses qui figurent sur ma TODO liste depuis quelques années et que j'avais jusqu'ici remis à plus tard, en partie à cause de la situation dans laquelle je me trouvais précédemment avec Jekyll :
- Lancer une mailing-list. C’est prévu d’ici la fin du mois.
- Une nouvelle section pour les articles qui ne rentrent pas dans la section des articles techniques.
- Améliorer la qualité du code du site pour ne plus être embarrassée et rendre le dépôt public sur Github.
- Rendre le site disponible en mode offline. Et le rendre encore plus rapide.
- Il y aura une FAQ mais pas au format des AMA (Ask Me Anything) qu'on trouve sur GitHub. Il y a des aspects que je n'aime pas dans ce format. Plus d’informations et de détails dès que la lettre d’information paraîtra.
- Écrire plus régulièrement. Je laisse beaucoup trop d’idées de côté que je devrais transformer en articles de blog. Je me suis promise d’écrire plus souvent, même si ces idées d’articles ne sont pas aussi poussées que d’habitude. Cet article est un début.
Quelques mots de conclusion ?
Je laisserai à Agnès le soin d’exprimer ce que je ressens vis-à-vis de cette nouvelle configuration, même si je sais que je peux et que j'améliorerai encore quelques trucs dans le futur :
Au moins maintenant je dispose d’un système qui m'évitera des maux de tête à chaque changement que je voudrais apporter à mon site Web. Je prends de nouveau plaisir à écrire des articles de blog, ce qui veut dire que vous pouvez vous attendre à de prochaines publications dans les semaines à venir.
Merci de m'avoir lue jusqu'ici.
NdT: Il est vrai que le temps de compilation de Jekyll peut excéder plusieurs minutes quand vous compilez des centaines de pages, cela dépend des plugins que vous utilisez et de l’optimisation de vos templates Liquid. À titre de comparaison, pour ce blog, il n'excède pas les 10 secondes par défaut et à peine plus d’une seconde avec l’option
incrementalactivée. ↩NdT: Pour la petite histoire c'est Tom Preston-Werner, le créateur de Jekyll qui est à l’origine de TOML (d’où son nom). Vous pouvez apprendre TOML en quelques minutes, même chose pour YAML ↩
NdT: C’est inexact, Jekyll offre la possibilité de créer ses propres types de contenu avec les collections. ↩